본 포스팅은 노마드코더님의 온라인 강의에 대한 복습을 기록하기 위한 포스팅입니다.
※ 본 포스팅의 내용은 강의를 들은 후 필자의 개인적인 의견을 기재한 것이니, 정답이 아닐 수 있음을 참고하십시오.
강의 소개 : 파이썬으로 웹 스크래퍼 만들기 (2주 완성반)
-. 내용 : 파이썬 기초 (타입, 변수, 함수, 클래스 등 및 웹 스크래퍼 코드 작성법)
-. 비용 : 100% 무료 강의
-. 비고 : 한글 자막 제공 / 강의 100% 완료 시 10% 할인 쿠폰 제공
온라인 강의 : https://nomadcoders.co/ / 풀스택 개발자 로드맵 : https://nomadcoders.co/roadmap
유튜브 채널 : https://www.youtube.com/channel/UCUpJs89fSBXNolQGOYKn0YQ
노마드 코더 Nomad Coders
한국인 린과 콜롬비아인 니꼴라스의 프로젝트 "노마드 코더" 입니다. 2015년 떠나, 현재까지 원하는 곳에서 일하며, 살고 있습니다. + + Nomad Academy: https://nomadcoders.co
www.youtube.com
#4.4 Scrapper Integragion & #4.5 Faster Scrapper
1) Argument 값을 무조건 소문자로 받아오기
""" main.py """
from flask import Flask, render_template, request
app = Flask("Flask")
@app.route("/")
def home():
return render_template("home.html")
@app.route("/report")
def report():
word = request.args.get("word")
word = word.lower()
return render_template(
"report.html",
searchingBy = word
)
app.run(host="0.0.0.0")
-. string.lower()와 같이 입력 해줄 경우 string의 값을 소문자로 변경할 수 있습니다.

-. 하지만 "word"라는 argument의 값이 없을 경우 위 사진과 같이 에러가 발생하는 것을 보실 수 있습니다.
-. 왜냐하면 argument의 값이 없을 경우 word라는 변수에 None Type이 저장되기 때문입니다.
""" main.py """
from flask import Flask, render_template, request
app = Flask("Flask")
@app.route("/")
def home():
return render_template("home.html")
@app.route("/report")
def report():
word = request.args.get("word")
if word:
word = word.lower()
return render_template(
"report.html",
searchingBy = word
)
app.run(host="0.0.0.0")
-. 그렇기 때문에 argument 값이 있을 경우 .lower()를 실행해주어야 합니다.
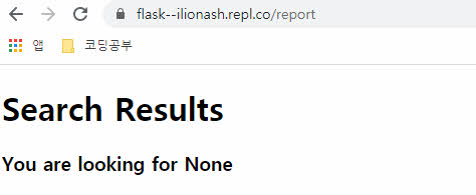
-. 이번에는 word 변수에 None Type이 저장되어 report.html에서 None이 출력되는 것을 보실 수 있습니다.
-. 하지만 우리가 원하는 사이트는 argument가 없을 때 report.html을 출력하는 것을 원하지 않습니다.
from flask import Flask, render_template, request, redirect
app = Flask("Flask")
@app.route("/")
def home():
return render_template("home.html")
@app.route("/report")
def report():
word = request.args.get("word")
if word:
word = word.lower()
else:
return redirect("/")
return render_template(
"report.html",
searchingBy = word
)
app.run(host="0.0.0.0")
-. 그렇기 때문에 위 코드와 같이 작성하여 argument가 없을 경우 home.html을 출력 하도록 설정할 수 있습니다.
-. redircet를 사용하기 위해서 "redirect" Function을 import 해주었습니다.
-. return redirect("/") : @app.route("/")를 호출하라는 뜻입니다.
2) Flask를 이용하여 Stackoverflow 사이트 Scrapping 하기
""" scrapper.py """
import requests
from bs4 import BeautifulSoup
def extract_pages(URL):
result = requests.get(URL)
soup = BeautifulSoup(result.text, "html.parser")
pages = soup.find("div", {"class":"s-pagination"})
if pages:
pages = pages.find_all("a")
last_page = pages[-2].get_text(strip=True)
else:
last_page = 1
return int(last_page)
def extract_job(html):
title = html.find("h2").find("a")["title"]
company, location = html.find("h3").find_all("span", recursive=False)
company = company.get_text(strip=True)
location = location.get_text(strip=True).strip("-").strip(" \r").strip("\n")
job_id = html["data-jobid"]
return{
"title": title,
"company": company,
"location": location,
"link": f"https://stackoverflow.com/jobs/{job_id}"
}
def extract_jobs(URL, last_pages):
jobs = []
for page in range(last_pages):
print(f"Scrapping page : {page}")
result = requests.get(f"{URL}&pg={page+1}")
soup = BeautifulSoup(result.text, 'html.parser')
# Indeed에서 각 직업별 정보를 리스트로 가져오기
results = soup.find_all("div", {"class": "-job"})
# 여러개의 결과에서 1개 일자리에 대한 정보 찾기
for result in results:
job = extract_job(result)
jobs.append(job)
return jobs
def get_jobs(word):
# 스크래핑 하려는 URL 저장
URL = f"https://stackoverflow.com/jobs?q={word}"
# "indeed" Object의 "extract_pages" Function 호출
last_page = extract_pages(URL)
# "indeed" Object의 "extract_jobs" Function 호출
jobs = extract_jobs(URL, last_page)
return jobs
-. 우선 이전에 Stackoverflow를 스크랩하는 코드를 가지고 와서 약간 만 수정하였습니다.
* URL을 "get_jobs" function 내부로 넣어주고, 검색어를 "python" 에서 word라는 변수를 받도록 수정하였습니다.
""" main.py """
from flask import Flask, render_template, request, redirect
from scrapper import get_jobs
app = Flask("Flask")
@app.route("/")
def home():
return render_template("home.html")
@app.route("/report")
def report():
word = request.args.get("word")
if word:
word = word.lower()
jobs = get_jobs(word)
print(jobs)
else:
return redirect("/")
return render_template(
"report.html",
searchingBy = word
)
app.run(host="0.0.0.0")
-. from scrapper import get_jobs
* "scrapper.py" 파일에 있는 "get_jobs" Function을 import 해줍니다.
-. jobs = get_jobs(word)
* argument로 의 값을 word 변수에 저장 후 "get_jobs" Function을 실행하고, 결과 값을 jobs 변수에 저장합니다.
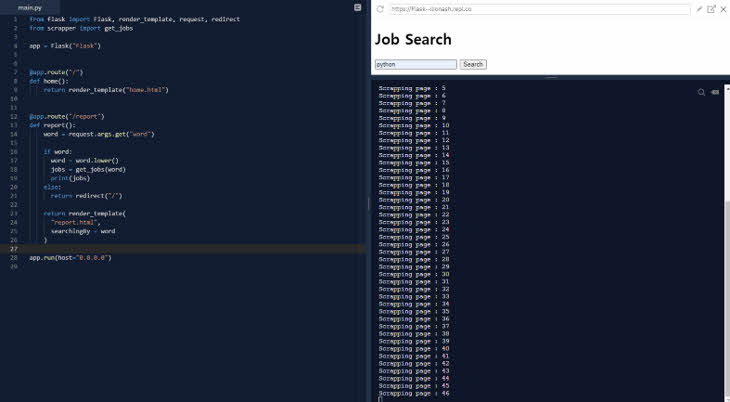
-. 위 사진과 같이 stackoverflow 사이트에서 각 페이지 별로 직업 정보를 가지고 오고 있는 모습을 보실 수 있습니다.
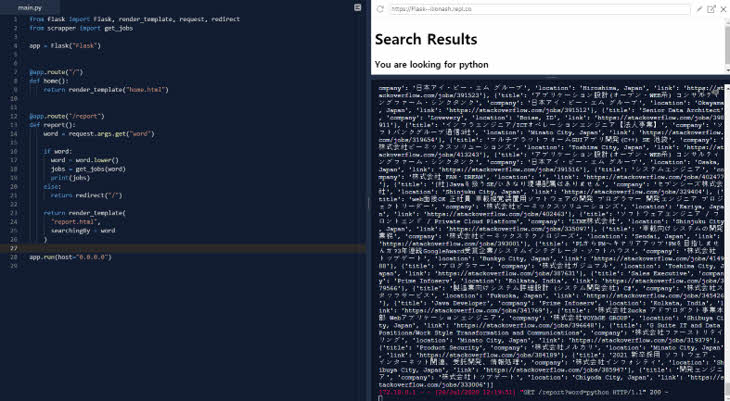
-. 최종적으로 전체 페이지에서 가지고 온 직업 정보들이 출력되는 모습을 보실 수 있습니다.
※ 본 포스팅의 내용은 강의를 들은 후 필자의 개인적인 의견을 기재한 것으로,
정답이 아닐 수 있음을 참고하십시오.
이상으로 Python으로 웹 스크래퍼 만들기 복습 11일 차를 마치겠습니다.




