본 포스팅은 노마드코더님의 온라인 강의에 대한 복습을 기록하기 위한 포스팅입니다.
※ 본 포스팅의 내용은 강의를 들은 후 필자의 개인적인 의견을 기재한 것이니, 정답이 아닐 수 있음을 참고하십시오.
강의 소개 : 파이썬으로 웹 스크래퍼 만들기 (2주 완성반)
-. 내용 : 파이썬 기초 (타입, 변수, 함수, 클래스 등 및 웹 스크래퍼 코드 작성법)
-. 비용 : 100% 무료 강의
-. 비고 : 한글 자막 제공 / 강의 100% 완료 시 10% 할인 쿠폰 제공
온라인 강의 : https://nomadcoders.co/ / 풀스택 개발자 로드맵 : https://nomadcoders.co/roadmap
유튜브 채널 : https://www.youtube.com/channel/UCUpJs89fSBXNolQGOYKn0YQ
노마드 코더 Nomad Coders
한국인 린과 콜롬비아인 니꼴라스의 프로젝트 "노마드 코더" 입니다. 2015년 떠나, 현재까지 원하는 곳에서 일하며, 살고 있습니다. + + Nomad Academy: https://nomadcoders.co
www.youtube.com
#2.3 Extracting Indeed Pages & #2.4 Extracting Indeed Pages part Two &
#2.5 Requesting Each Page
1) 구글 크롬 브라우저에서 웹사이트의 html 소스 코드 확인하기
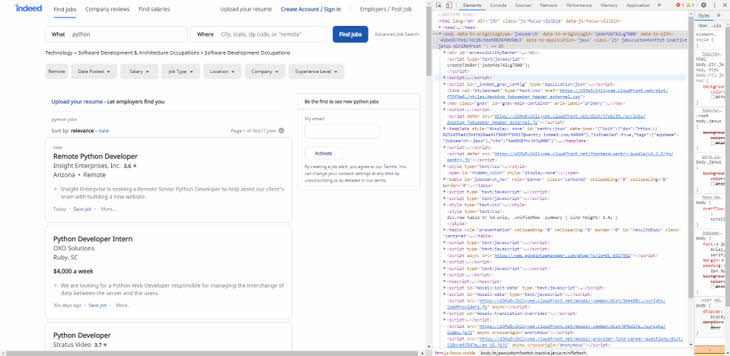
-. 웹 사이트에 접속하여서 "F12"키를 누르거나 "마우스 우클릭 -> 페이지 소스 코드 보기" 클릭
2) Indeed 웹 사이트에서 Page와 관련된 부분의 소스 코드 확인하기
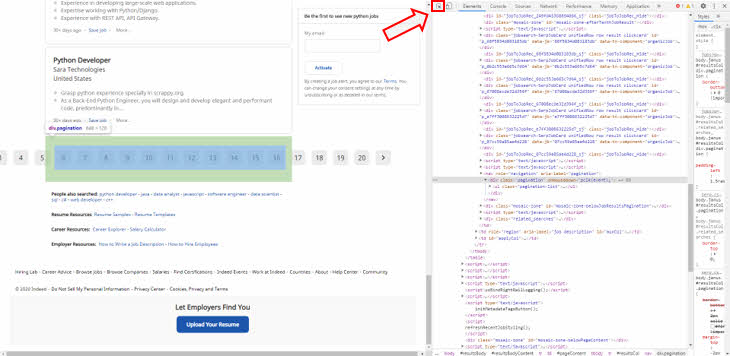
-. "Select an element inthe page to inspect it" 버튼 클릭 후 Page 번호가 있는 곳 클릭
3) HTML Tag를 이용하여 필요한 부분 가져오기
-. beautiful4에서 제공하는 find() / find_all() Function을 이용하여 특정 Tag의 값 가져오기
find() : 해당 Tag 중 첫 번째에 해당하는 값 1개만 가져옴
-. find("div") = 전체 html 중 첫 번째 div Tag의 값만 가지고 옴
find_all() : 해당 Tag의 모든 값을 리스트로 가지고옴
-. find_all("div") = 전체 html에 있는 모든 div Tag의 값을 리스트로 가지고 옴
Tag 특정하기 : 각 Tag의 class, name, id 등의 정보를 이용하여 특정 Tag의 값만 가져오기
-. find("div", {"class":"pagination"}) = div Tag 중 Class가 paginaion인 첫 번째 것의 값만 가지고 옴
-. find_all("span", {"class":"pn"} = span Tag 중 Class가 pn인 모든 것의 값을 리스트로 가지고 옴
4) Web Scrapping 소스 코드 (GitHub 각 강의별 Version Control)
main.py
from indeed import extract_indeed_pages, extract_indeed_jobs
# "indeed" Object의 "extract_indeed_pages" Function 호출
last_indeed_pages = extract_indeed_pages()
# "indeed" Object의 "extract_indeed_jobs" Function 호출
extract_indeed_jobs(last_indeed_pages)indeed.py
import requests
from bs4 import BeautifulSoup
LIMIT = 50
# 스크래핑 하려는 INDEED_URL 저장
URL = f"https://www.indeed.com/jobs?q=python&limit={LIMIT}"
# "Indeed" 웹사이트를 스크래핑 하는 Function 생성
def extract_indeed_pages():
# url에 저장된 웹사이트를 requestsdml get Function을 사용하여 가져오기
result = requests.get(URL)
# # html을 text로 가져오기
# print(result.text)
# bs4를 이용하여 "Indeed" 검색 결과를 html로 가져오기
soup = BeautifulSoup(result.text, 'html.parser')
# "div" Tag 중 Class가 "pagination"인 것 가져오기
pagination = soup.find("div", {"class" : "pagination"})
# "pagination" 변수에 저장된 html 중에서 "anchor" Tag 인 것 모두 가져와서 리스트로 저장
links = pagination.find_all("a")
# span을 저장할 빈 리스트 객체 생성
pages = []
# "links" 리스트에 저장된 값을 차례대로 "link"라는 객체로 받아온 후 "span" Tag 인 것을 "pages" 리스트에 추가
# [:-1] = "links" 리스트에 저장된 값 중 마지막 값을 제외한다는 뜻
for link in links[:-1]:
# pages.append(link.find("span").string)
# anchor Tag의 String을 가지고 와도 span의 String을 가지고 온다
pages.append(int(link.string))
# # "pages" 리스트에 저장된 값 중 마지막에서 1번째 item
# print(pages[-1])
# "pages"에 저장된 값 중 가장 큰 값(마지막 값)만 가져오기
max_page = pages[-1]
return max_page
def extract_indeed_jobs(last_pages):
for page in range(last_pages):
result = requests.get(f"{URL}&start={page*LIMIT}")
print(result.status_code)
※ 본 포스팅의 내용은 강의를 들은 후 필자의 개인적인 의견을 기재한 것으로,
정답이 아닐 수 있음을 참고하십시오.
이상으로 Python으로 웹 스크래퍼 만들기 복습 5일 차를 마치겠습니다.

#노마드코더 #파이썬 #웹스크래퍼 #온라인 코딩 #파이썬 강의 #풀스택 #크롤링 #프로그래밍 언어 #웹개발 #repl
'Python으로 웹 스크래퍼 만들기' 카테고리의 다른 글
| Python으로 웹 스크래퍼 만들기 복습 7일차 (Feat. 노마드코더) (0) | 2020.07.23 |
|---|---|
| Python으로 웹 스크래퍼 만들기 복습 6일차[find(), find_all(), Attribute, strip(), lstrip(), rstrip(), import] (Feat. 노마드코더) (0) | 2020.07.21 |
| Python으로 웹 스크래퍼 만들기 복습 4일차[웹스크래퍼] (Feat. 노마드코더) (0) | 2020.07.19 |
| Python으로 웹 스크래퍼 만들기 복습 3일차[If-Else 조건문, For 반복문] (Feat. 노마드코더) (0) | 2020.07.18 |
| Python으로 웹 스크래퍼 만들기 복습 2일차[함수, 매개변수, return] (Feat. 노마드코더) (0) | 2020.07.17 |



